Фонд содействия инновациям подвел итоги конкурсного отбора по программе “СТАРТ-2”. Всего на конкурс было подано 160 заявок из 47 субъектов Российской Федерации на общую сумму 1,2 млрд руб. В результате были определены 14 победителей, в том числе и мы, Picvario. Эта федеральная поддержка будет направлена на расширение функционала платформы.
Простыми словами о проекте
Проект предполагает разработку функционала для обогащения метаданных актива на основе ранее загруженных активов, а также еще более “умного” поиска активов с похожим набором метаданных. С помощью этой разработки конечный пользователь получит максимальную отдачу от заполнения метаданных.
А теперь более детально
Ниже в статье мы расскажем подробно о проекте, но это требует понимания некоторой терминологии. Приводим ее ниже.
Семантика – это раздел лингвистики, устанавливающий отношения между символами и объектами, которые они обозначают. Это наука, определяющая смысл знаков. Семантической сетью обычно называют «смысловую сеть», представленную в виде ориентированного графа, вершинами которого являются объекты предметной области, а дугами – отношения между ними.
Семантический поиск — способ и технология поиска информации, основанная на использовании контекстного (смыслового) значения запрашиваемых фраз, вместо словарных значений отдельных слов или выражений при поисковом запросе. При семантическом поиске учитывается информационный контекст, местонахождение и цель поиска пользователя, словесные вариации, синонимы, обобщенные и специализированные запросы, язык запроса, а также другие особенности, позволяющие получить соответствующий результат.
Интеллектуальный анализ данных — это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах деятельности. Данные, которые могут быть использованы для интеллектуального анализа данных, могут быть различных типов: текст, изображение, звук, числовые данные и т. д.
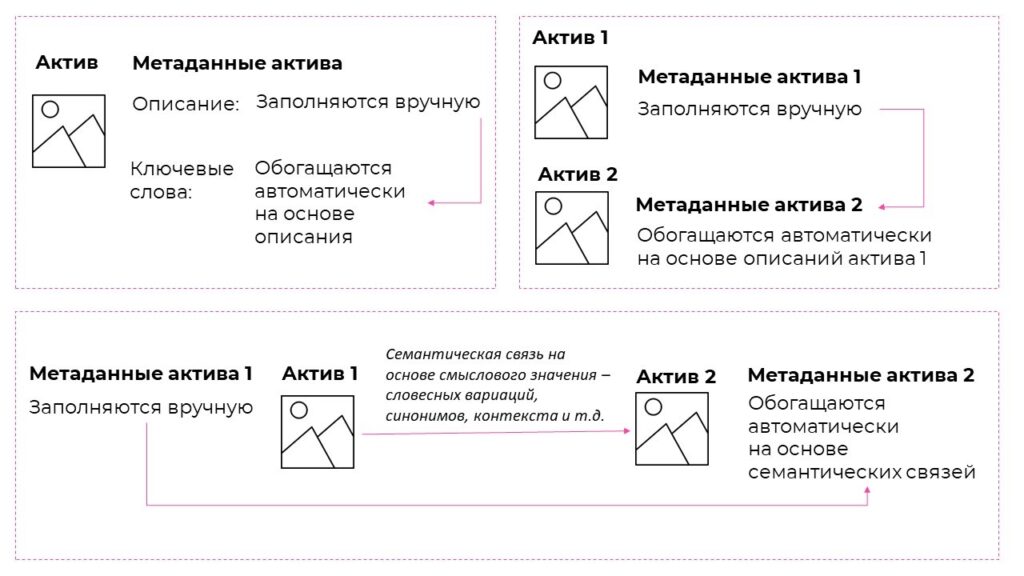
Цифровой актив (с англ. digital asset ) — это все, что существует только в цифровой форме, содержит метаданные и поставляется с определенным правом использования. Данные, которые не обладают этим правом, не считаются активами. К цифровым активам относится любой мультимедийный файл, фотография, видео, документ и т. д., который можно хранить и совместно использовать виртуально в цифровой форме. В статье под цифровым активом мы будем понимать изображение с заполненными метаданными.
Метаданные — данные о данных, которые содержат описательную информацию о файле, например, название, описание, ключевые слова, дату создания и автора цифрового актива.
Согласно проекта планируется разработка ниже описанного функционала.
1. Обогащение метаданных цифровых активов
Предпосылки
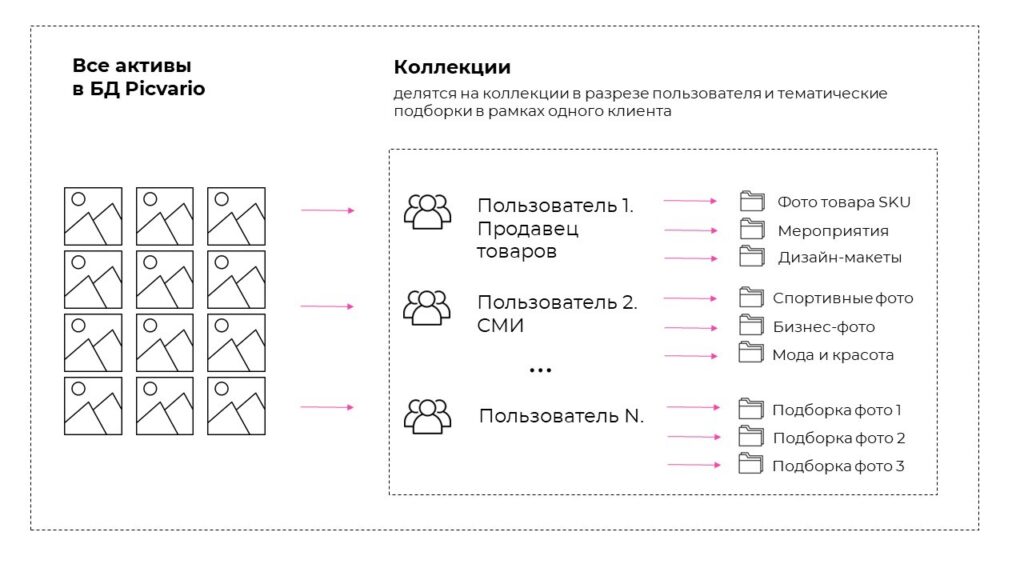
В Picvario цифровые активы разделены на коллекции как различных клиентов с определенной спецификой, так и тематические коллекции в рамках одного клиента. При этом объекты на изображениях в разных коллекциях и их метаданные могут сильно отличаться.
Для возможности поиска и управления цифровыми активам пользователи заполняют метаданные. Заполнение метаданных вручную — трудоемкий процесс, который в современных DAM-системах автоматизируют с помощью внедрения искусственного интеллекта (далее — ИИ). Но есть и подвох — нейросеть “выдрессирована” распознавать с высоким % достоверности объекты, которые были представлены в обучающей выборке. Другими словами, если при обучении в дата-сете ИИ было много крокодилов, то “в бою” нейросеть будет распознавать их с низким % ошибок, а вот с прочими рептилиями может быть погрешность.
Таким образом, возникает необходимость обучать отдельную модель для каждой коллекции. Это требует больших объемов атрибутированных изображений — проще говоря, каждый клиент должен вручную описать метаданные большого количества активов.
Решение
В рамках первого этапа программы Старт-1 был разработан прототип, который автоматически генерирует или обогащает существующую таксономию активов без метаданных. На втором этапе Старт-2 этот подход будет применен и к задаче обогащения метаданных активов.
Это позволит реализовать рекомендации:
- по заполнению ключевых слов на основе описания цифрового актива
- по заполнению метаданных цифрового актива на основе метаданных похожих цифровых активов
- по заполнению метаданных на основе семантических связей.
2. Подбор цифровых активов
Интеллектуальный анализ данных и семантические технологии позволяют подбирать активы на основе оценки сходства или релевантности по отношению к другим активам.
Это такие примеры, как сходство изображений друг с другом, так и сходство по оценке релевантности изображений к тексту.
2.1 Подбор похожих изображений
Сходство цифровых активов между собой может быть оценено:
- на основе их метаданных
- по степени их семантической связанности
- непосредственно по сходству их содержимого.
При просмотре некоторого изображения в интерфейсе могут быть представлены похожие изображения, которые могут оказаться более предпочтительным, чем исходное изображений.
2.2 Подбор изображений на основе текста
Степень соответствия изображений по отношению к тексту возможно оценить на основе того, насколько тексту соответствуют их метаданные. Это возможно даже при отсутствии метаданных благодаря механизмам распознавания объектов и др. способов обогащения метаданных.
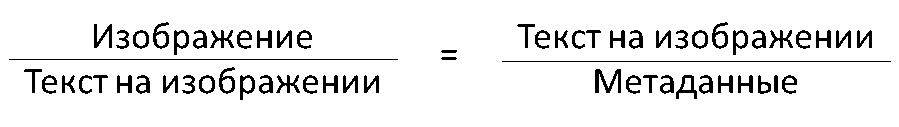
Подбор изображений на основе текста может быть использован при поиске иллюстраций к текстам.
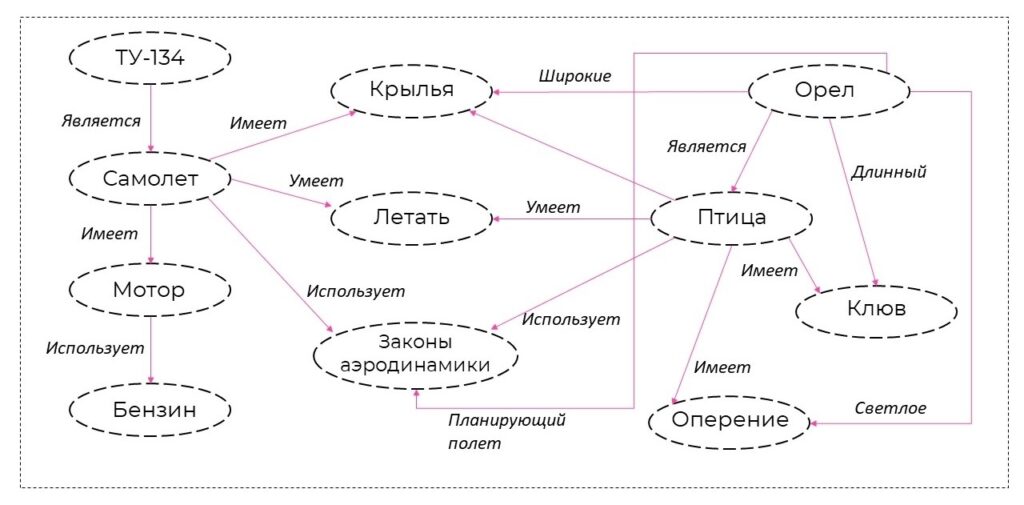
3. Формирование графов знаний цифровых активов
Эффективность управления цифровыми активами зависит от того, на сколько структурирован архив. В качестве такой структуры может использоваться иерархия (таксономия в Picvario). В рамках первого этапа был разработан прототип, который автоматически генерирует либо обогащает существующую таксономию активов, где в качестве признаков таксона выступают метаданные активов.
На основе признаков (метаданных) и таксономии актива будут различными методами формироваться их отношения. Это позволит выстраивать графы знаний.
Графы позволят реализовать:
- выдачу рекомендации об активах, связанных с текущими
- семантический поиск по цифровым активам
- семантический сторителлинг.
3.1 Выдача рекомендации об активах, связанных с текущими
Такие рекомендации могут избавить пользователей от поиска нужных изображений.
Например, пользователь вводит запрос “Домашний+матч+клуба+А” и выбирает в поисковой выдаче изображения игроков клуба. Система знает, что домашние матчи этого клуба проходят на стадионе Б, поэтому рекомендует изображение нужного стадиона. Пользователю не нужно искать его самостоятельно.
3.2 Семантический поиск по цифровым активам
Предпосылки
Полнотекстовый тип поиска разбивает запрос на так называемые ключи и ищет по каждому отдельному ключу. Поэтому в выдаче возможны нерелевантные активы.
Например, пользователь ищет матчи клуба Манчестер Юнайтед, прошедшие на стадионе Олд Траффорд. Для этого он вводит полнотекстовый запрос “football match of Manchester Utd was on the Old Trafford”, а система разбивает запрос на ключи “football match + Manchester Utd + the Old Trafford”, поэтому результат может содержать такие нерелевантные активы как изображения матча на другом стадионе или сооружение стадиона.
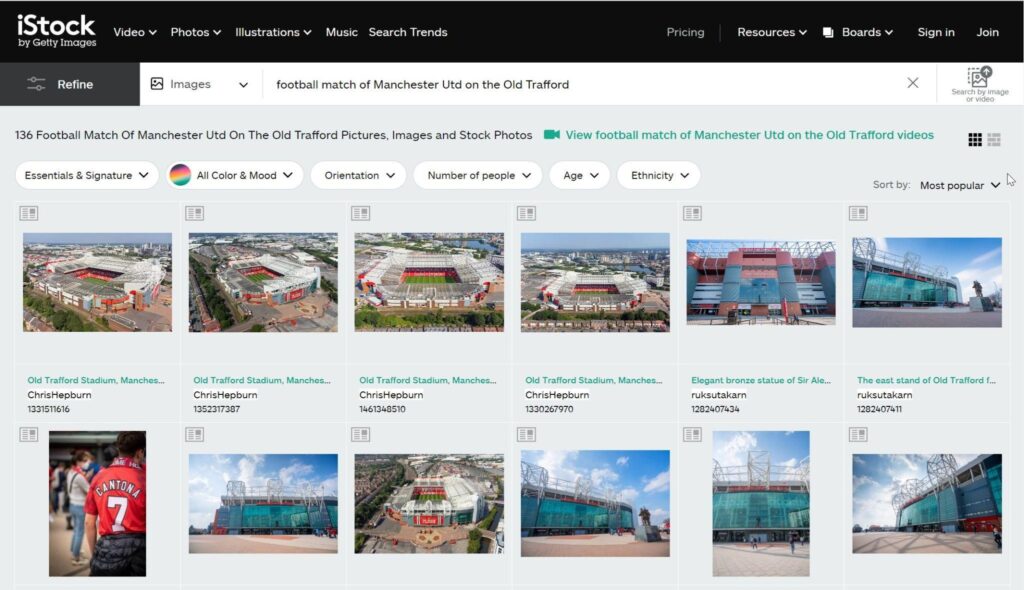
Решение
Семантический поиск является более полным и точным, так как осуществляет не только поиск по точному ключевому запросу, но учитывает и другие факторы, включая текущие тенденции, цели поиска, вариации слов и лингвистические особенности языка, синонимы, общие и специализированные запросы, зависимость между значением фразы и использованными в ней словами и т.д. (самый очевидный пример такого поиска — строка Google).
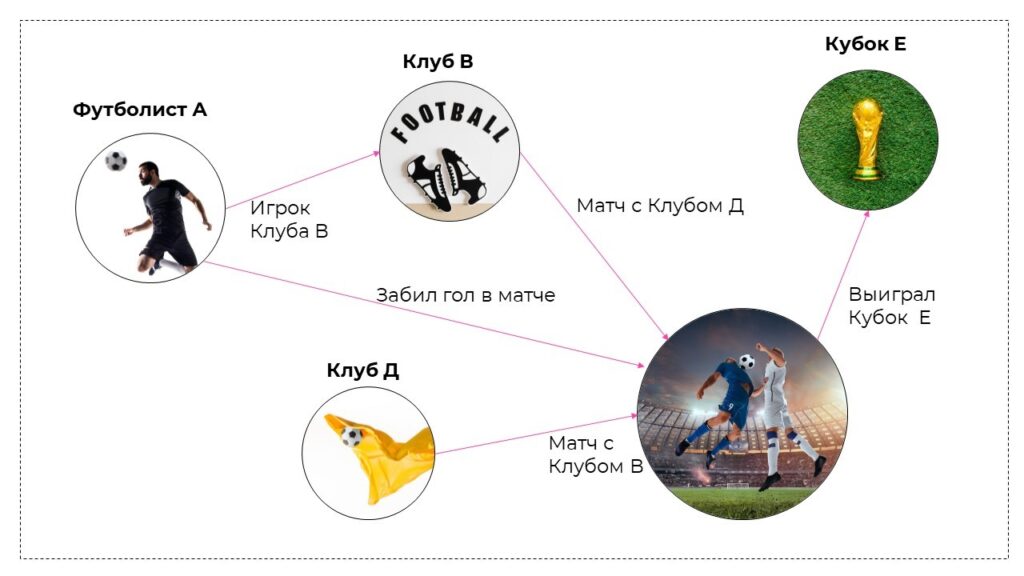
3.3 Семантический сторителлинг
Цифровые активы, сопровождающие некоторое текстовое повествование и связанные семантическими отношениями, формируют коллекции изображений, обладающие определенной структурой. Такая структура может быть автоматически извлечена, сохранена в виде шаблона и повторно использоваться.
Например, редактору необходимо подготовить публикацию о финале чемпионата, в котором футболист А, играющий за клуб В, забил решающий гол в матче с клубом Д. Это позволила клубу В выиграть кубок Е. При этом редактор использует соответствующие изображения футболиста, обоих клубов и кубка. Эти изображения можно связать отношениями “забил гол в матче”, “матч с” и “выиграл кубок”, сохранить этот набор связей как шаблон и впоследствии при подготовке новых публикаций о решающем голе в матче любых двух команд за некоторый кубок автоматически формировать аналогичные наборы активов.